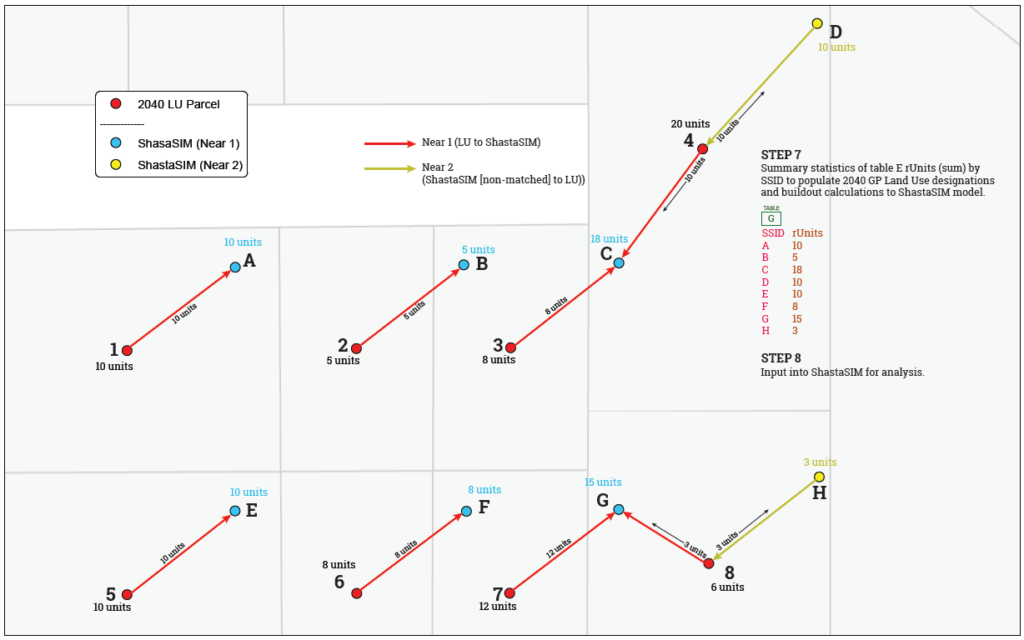
For our work in updating the traffic analysis in Shasta Lake’s General Plan EIR, we’ve had to think up a way to bridge two different datasets representing the same thing. We’ve developed build out information on Shasta Lake’s latest parcel dataset but we’ve got to map and reallocate the calculations to the Shasta SIM model – which has required inputs reflected an older parcel dataset. There are many discrepancies in the location and counts of data. There are 1:many, many:1, many:many, and 1:1 relationships between these datasets.
The image below is a peek at the visual from our documentation – basically we disperse or consolidate build out data to reflect the discrepancies between the two datasets while retaining the overall summary data.